Processing Step
데이터 전/후처리, 피처 엔지니어링, 데이터 검증, 모델 평가 등의 작업은 Processing Step으로 표현한다. 그러나 컨테이너가 머신 러닝 관련 라이브러리들이 미리 설치된 파이썬 스크립트 실행기라고 본다면 거의 모든 작업을 Processing Step에서 처리할 수 있다.
Processor
Processing Step은 Processing Job을 ML Pipeline의 구성요소로 만든 것이다. 따라서 Processing Job을 먼저 이해해야 한다.
Processing Job은 Processor 클래스의 인스턴스를 만드는 것으로 시작한다. Processor 클래스는 모든 Processor 클래스의 부모 클래스로, 가장 기본적인 기능만 들어있다. 대표적으로 Processor 인스턴스는 컨테이너가 실행될 때 추가적인 라이브러리를 설치하는 것이 불가능하다. 오로지 프로세서를 실행할 때 전달하는 파이썬 스크립트만 실행한다.
Framework Processor
Processor의 서브 클래스로, 지정한 머신 러닝 프레임워크로 processing job을 실행한다. AWS에서는 Hugging Face, MXNet, PyTorch, TensorFlow, XGBoost 등을 미리 만들어진 컨테이너를 제공하며, 이에 대한 서브클래스들이 각각 존재한다.
Framework Processor들은 컨테이너에 설치할 Python 라이브러리를 requirements.txt 에 적어두면 스크립트를 실행하기 전 라이브러리를 설치해준다.
클래스의 인터페이스를 확인하고 싶다면 SageMaker SDK 문서에서 확인할 수 있다.
Processing Job 실행 방식
AWS 공식문서에 Processing Job 컨테이너가 어떻게 실행되는지를 그림으로 그려두었다.

Processing Job은 입력 데이터를 S3 버킷에 저장해두어야 한다. Amazon Athena 또는 Redshift도 입력 소스로 지원한다.
입력 데이터는 컨테이너 안에서 /opt/ml/processing/input 경로 안에 마운트된다. 따라서 입력 데이터를 접근하기 위해서는 파이썬 스크립트가 해당 경로 안에서 파일을 찾아야 하는 것이다.
입력 데이터를 잘 찾아내 로드했다면, 개발자가 작성한 스크립트를 실행한 뒤 그 결과물도 정해진 위치에 잘 저장해야 한다. 저장할 때는 /opt/ml/processing/output 경로 아래에 저장해야 한다.
Processor 인스턴스 만들기
위 내용을 참고하여 Processor 인스턴스를 선언해본다면 다음과 같이 할 수 있다.
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterString,
)
from sagemaker.processing import FrameworkProcessor
from sagemaker.sklearn.estimator import SKLearn
processing_instance_count = ParameterInteger(
name="ProcessingInstanceCount",
default_value=1
)
processing_instance_type = ParameterString(
name="ProcessingInstanceType",
default_value="ml.t3.large"
)
framework_processor = FrameworkProcessor(
command=["python3"],
instance_type=processing_instance_type,
instance_count=processing_instance_count,
estimator_cls=SKLearn,
framework_version="1.0-1",
role=role,
sagemaker_session=pipeline_session,
)위 예제는 Scikit-Learn 프레임워크가 설치된 인스턴스를 사용하는 Processor를 선언한 것이다. 각 Parameter를 하나씩 살펴보도록 하자.
command: 커맨드라인에 플래그를 추가해야 한다면 이 파라미터를 이용하면 된다. 예를 들면,["python3", "-v"]처럼 해볼 수 있다. 기본 값은["python"]이다.instance_type: EC2 인스턴스의 스펙을 지정할 수 있다. 이 예제에서는ParameterString을 사용했는데, 이는 SageMaker Pipeline에서 사용하는 것이다. 파이프라인을 실행할 때name과 값을 키-값 쌍으로 전달하면 파이프라인이 실행될 때 전달한 값이 사용된다.- 사용할 수 있는 인스턴스 타입은 AWS SageMaker 요금 페이지에서 확인할 수 있다.
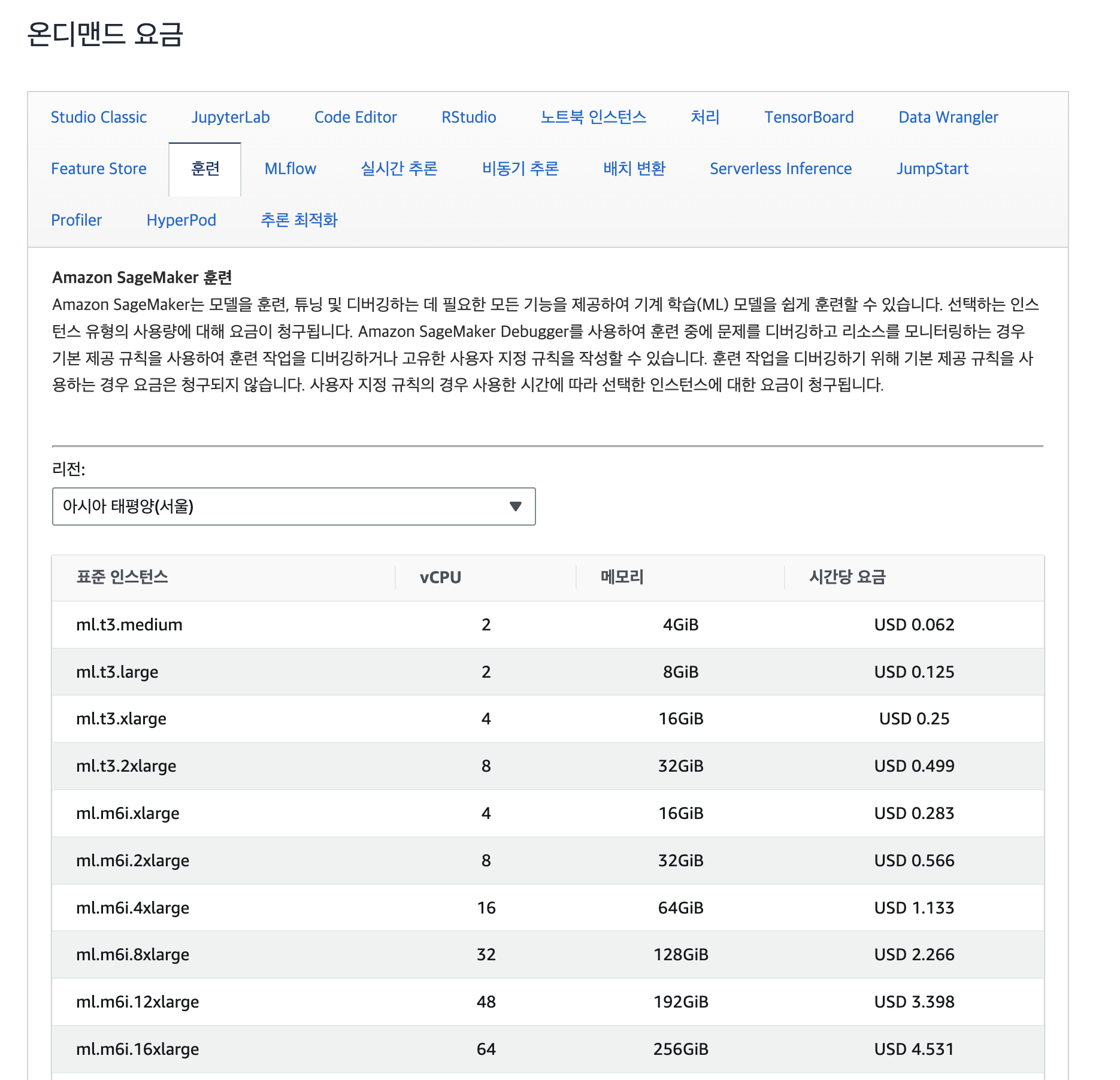
instance_type: Processing Job을 수행할 인스턴스의 수를 지정한다.estimator_cls: 프레임워크 estimator의 서브클래스를 전달한다. 여기에 전달한 값과framework_version의 값의 조합은 AWS에서 미리 만들어 둔 이미지 프리셋에 있어야 한다.framework_version: 사용할 프레임워크의 버전을 명시한다. 각 프레임워크마다 사용할 수 있는 버전이 정해져있다. AWS SageMaker ECR 경로 문서를 보면 사용할 수 있는 버전이 어떤 것인지 알 수 있다.role: Processing Job을 실행하는 EC2 인스턴스에 할당할 역할. 편의 상get_execution_role()의 결과를 많이 사용했다.sagemaker_session:Session인스턴스. ML Pipeline 내에서 실행되어야 한다면 반드시PipelineSession의 인스턴스를 전달해야 한다. 일반Session인스턴스를 전달한다면 나중에 볼run()메소드를 실행하는 순간 Processing Job이 즉시 실행된다.- Training Step, Batch Transform Step 등에서도 동일하다. 파이프라인에서 실행하고 싶다면 반드시
PipelineSession의 인스턴스를 전달하자.
- Training Step, Batch Transform Step 등에서도 동일하다. 파이프라인에서 실행하고 싶다면 반드시
사실 Scikit-Learn은 SKLearnProcessor 라는 클래스가 별도로 존재한다. 내 기억으로는 SKLearnProcessor 는 requirements.txt를 만들어도 이를 무시했던 것 같다. requirements.txt가 필요하다면 FrameworkProcessor 를 사용하도록 하자.
Processing Step Argument 만들기 - run()
이렇게 만들어진 Processor 인스턴스는 run() 이라는 메소드를 가지고 있다. 이 함수를 호출하면 즉시 Processing Job이 실행되는데, PipelineSession을 전달했다면 작업이 실행되는 대신 파이프라인을 정의하는데 사용할 Step Argument 들이 반환된다.
예시를 보면 다음과 같다.
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.workflow.functions import Join
dataset_name = ParameterString(
name="DatasetName",
)
input_path = "/opt/ml/processing/input"
output_path = "/opt/ml/processing/output"
train_output_prefix = "train"
test_output_prefix = "test"
holdout_output_prefix = "holdout"
output_train_filename = "train.parquet"
output_test_filename = "test.parquet"
output_holdout_filename = "holdout.parquet"
processor_args = framework_processor.run(
inputs=[
ProcessingInput(
source=Join(on="/", values=[base_dir, "source"]),
destination=input_path,
),
],
outputs=[
ProcessingOutput(
output_name="train",
source=f"{output_path}/{train_output_prefix}",
destination=Join(on="/", values=[base_dir, dataset_name, "preprocess", train_output_prefix]),
),
ProcessingOutput(
output_name="test",
source=f"{output_path}/{test_output_prefix}",
destination=Join(on="/", values=[base_dir, dataset_name, "preprocess", test_output_prefix]),
),
ProcessingOutput(
output_name="holdout",
source=f"{output_path}/{holdout_output_prefix}",
destination=Join(on="/", values=[base_dir, dataset_name, "preprocess", holdout_output_prefix]),
),
],
code="preprocess/preprocess.py",
source_dir="pipelines",
arguments=[
"--input_path", input_path,
"--output_path", output_path,
"--output_train_file_prefix", train_output_prefix,
"--output_test_file_prefix", test_output_prefix,
"--output_holdout_file_prefix", holdout_output_prefix,
"--output_train_filename", output_train_filename,
"--output_test_filename", output_test_filename,
"--output_holdout_filename", output_holdout_filename,
],
)각 파라미터들을 하나씩 살펴보자.
input: Processing Job의 입력 데이터들을 매핑하기 위해 사용한다. 여기에는ProcessingInput이라는 클래스의 인스턴스가 필요하다. 예제에서는base_dir/source디렉토리를/opt/ml/processing/input에 연결했다(base_dir은s3://my-bucket/pipeline과 같은 S3 URI이다).output: Processing Job의 실행 결과물들의 저장 위치를 S3 위치와 매핑하기 위해 사용한다.output_name: Processing Job 의 결과물들을output_name으로 지정한 이름에 할당한다. 이는 나중에 다른 작업(또 다른 Processing Job이나 학습, 배치 등)에서 결과물을 참조하기 위해 사용된다.source: 컨테이너 내에 파일이 저장되는 곳이다. 경로는/opt/ml/processing/output으로 시작해야 한다.destination: 저장된 파일이 위치할 S3 경로를 넣어준다. 여기서는 특이하게Join이라는 유틸 함수를 사용했는데,dataset_name과 같이 그 값이 나중에 resolve 되는 성격의 값이 존재한다면Join이라는 유틸 함수를 사용해서 값이 나중에 평가될 수 있도록 한다.
source_dir: Processing Job이 실행할 코드는source.tar.gz라는 이름으로 아카이빙되어 S3 어딘가에 저장되고, 컨테이너가 이를 가져가 코드를 실행하게 된다.source_dir에 Jupyter notebook이 참조할 수 있는 디렉토리 경로를 적어주면, 그 경로가source.tar.gz내code디렉토리가 된다.code:code디렉토리에서 프로그램 진입점이 있는 파이썬 스크립트를 지정해주면 된다.- 예시로 보면, Jupyter notebook 파일 구조는 다음과 같은 형태가 되어 있는 것이다.
. ├──pipelines │ ├── preprocess │ │ ├── preprocess.py │ │ └── requirements.txt │ └── ... └── sagemaker_pipeline.ipynb
arguments: 파이썬 스크립트를 실행할 때 argument로 전달할 인자 목록을 적는다.
Processing Job 스크립트 예시
스크립트의 형태가 강제된 것은 아니지만, 아래의 형태와 거의 유사하게 작성될 것이다. 입력 데이터를 불러오고 데이터를 저장하는 부분을 잘 참고하면 좋다.
import argparse
import os
import pandas as pd
from sklearn.model_selection import train_test_split
def read_parameters():
"""
Read job parameters
Returns:
(Namespace): read parameters
"""
parser = argparse.ArgumentParser()
parser.add_argument("--train_size", type=float, default=0.8)
parser.add_argument("--test_size", type=float, default=0.2)
parser.add_argument("--holdout_size", type=float, default=0.12)
parser.add_argument("--input_path", type=str, default="/opt/ml/processing/input")
parser.add_argument("--output_path", type=str, default="/opt/ml/processing/output")
parser.add_argument("--output_train_file_prefix", type=str)
parser.add_argument("--output_test_file_prefix", type=str)
parser.add_argument("--output_holdout_file_prefix", type=str)
parser.add_argument("--output_train_filename", type=str)
parser.add_argument("--output_test_filename", type=str)
parser.add_argument("--output_holdout_filename", type=str)
params, _ = parser.parse_known_args()
return params
def parquets_to_df(dir_path: str) -> pd.DataFrame:
"""
경로에 있는 모든 parquet 파일을 읽어서 하나의 DataFrame으로 합친다.
Args:
dir_path: 디렉토리 경로
Returns: DataFrame
"""
parquet_files = [f for f in os.listdir(dir_path) if f.endswith(".parquet")]
df_list = [pd.read_parquet(os.path.join(dir_path, file)) for file in parquet_files]
return pd.concat(df_list)
def process_data(args, df):
# Holdout from data
rest_df, holdout_df = train_test_split(
df, test_size=args.holdout_size
)
train_df, val_df = train_test_split(rest_df, test_size=args.test_size)
return train_df, val_df, holdout_df
def save_to_parquet(df, output_path, file_prefix, filename):
os.makedirs(os.path.join(output_path, file_prefix), exist_ok=True)
df.to_parquet(os.path.join(output_path, file_prefix, filename), index=False)
def main():
args = read_parameters()
df = parquets_to_df(f"{args.input_path}/raw_data")
train_df, val_df, holdout_df = process_data(args, df)
# Save datasets to Parquet
save_to_parquet(
train_df,
args.output_path,
args.output_train_file_prefix,
args.output_train_filename,
)
save_to_parquet(
val_df,
args.output_path,
args.output_test_file_prefix,
args.output_test_filename,
)
save_to_parquet(
holdout_df,
args.output_path,
args.output_holdout_file_prefix,
args.output_holdout_filename,
)
if __name__ == "__main__":
main()Processing Step 인스턴스 만들기
이제 스텝을 정의할 모든 준비가 끝났다. 다음과 같이 코드를 작성해볼 수 있다.
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.workflow.steps import CacheConfig
step_preprocess = ProcessingStep(
name=f"{pipeline_name}-Preprocess", step_args=processor_args,
cache_config=CacheConfig(enable_caching=True, expire_after="P30d")
)스텝 이름을 지정하고, run() 메소드의 결과를 step_args 에 넣으면 된다. 추가로 cache_config 를 넣어주었는데, 파이프라인을 실행할 때 전달한 파라미터의 값의 집합이 이전에 실행된 적이 있다면, 스크립트 코드 등이 변경되어 파이프라인 정의도 업데이트가 되지 않는 이상 작업이 다시 실행되지 않고 이전에 실행했던 작업 결과물을 그대로 사용한다. 보다 자세한 내용은 다른 글에서 다루도록 하겠다.
마무리
이렇게 Processing Step의 거의 모든 것에 대해 알아보았다. 다음에는 모델 학습을 위한 Training Step에 대해 작성할 것이다.
'Engineering > AWS SageMaker' 카테고리의 다른 글
| SageMaker Pipeline - Model 등록 & 생성 (0) | 2024.12.22 |
|---|---|
| SageMaker Pipeline - Tuning Step (0) | 2024.12.22 |
| SageMaker Pipeline - Training Step (0) | 2024.12.22 |
| SageMaker Pipeline - SDK, Session (0) | 2024.12.21 |
| SageMaker Pipeline - ML Pipeline을 위한 또 다른 선택지 (0) | 2024.12.21 |